

OmniVoice Studio最新版是ElevenLabs替代品软件,一款集成了全新的实时听写、语音克隆、影视级视频配音,让用户可以在这里体验本地化语音便捷制作。OmniVoice Studio免费版主打着就是开源免费,用户可以在这里体验多样化的语音编辑,无论是克隆还是分离,甚至都能在这里为视频配音,让用户轻松玩转每一个视频声音。
OmniVoice Studio最新版完全面向每一个用户,无论是个人还是公司企业都能使用,而且比ElevenLabs更加的免费,不用花钱就能使用,完全架构于本地端,不用担心自己的作品泄露。
软件特色
3 秒零样本语音克隆,646 种语言随意切换
只需要一段 3 秒干净音频,就能完整复刻任何人的声线,零样本无需训练,上传素材立刻生成语音。覆盖 646 种语言,不管各国小语种、国内各类方言都能适配,克隆完成后还能跨语言生成配音,用中文样本也能生成日语、英语、俄语旁白。
日常做解说、虚拟主播、有声书都够用,生成的人声自然流畅,没有机械电子音,还支持 A/B 双轨试听对比,方便挑选最合适的音色版本。
自定义声音设计,从零打造专属声线
不用参考音频也能自制全新人声,性别、年龄、口音、音高、语速、情绪、方言全部可调。想做沉稳中年旁白、温柔少女音、厚重播音腔、外国口音台词,拖动参数就能实时预览,调整好的音色一键存入本地声音库,后续项目直接调取,不用反复重新调节。
全链路视频自动配音,本地一键导出成片
支持上传本地视频,也能直接粘贴 YouTube 链接处理,整套流水线全自动完成:语音转录原文、多语种翻译、人声分离、重新配音、封装导出 MP 4。 内置 Demucs 人声分离模型,能把原视频人声和背景音乐、音效分开,完整保留原背景音,只替换配音;搭配 Pyannote 说话人分离,自动识别视频里多个人物,给不同角色分配独立克隆声线,做多人对话视频不用手动分段剪辑。批量队列功能支持一次拖入 50 条视频后台处理,不用守在电脑前等待。
全局实时听写工具,系统热键一键转文字
设置快捷键 ⌘+⇧+Space(Windows 替换对应组合键),任意软件界面都能启动听写,说话实时转文字自动粘贴,浮动窗口无痕隐藏,开会记录、采访录音转文稿、写脚本都很省事。底层搭载 WhisperX 模型,99 种语言精准识别,断句、字词对齐清晰,导出 SRT、VTT 字幕文件直接适配剪辑软件。
使用说明
语音克隆
拖入 3 秒音频 → 复制任何声音。646 种语言,零样本。
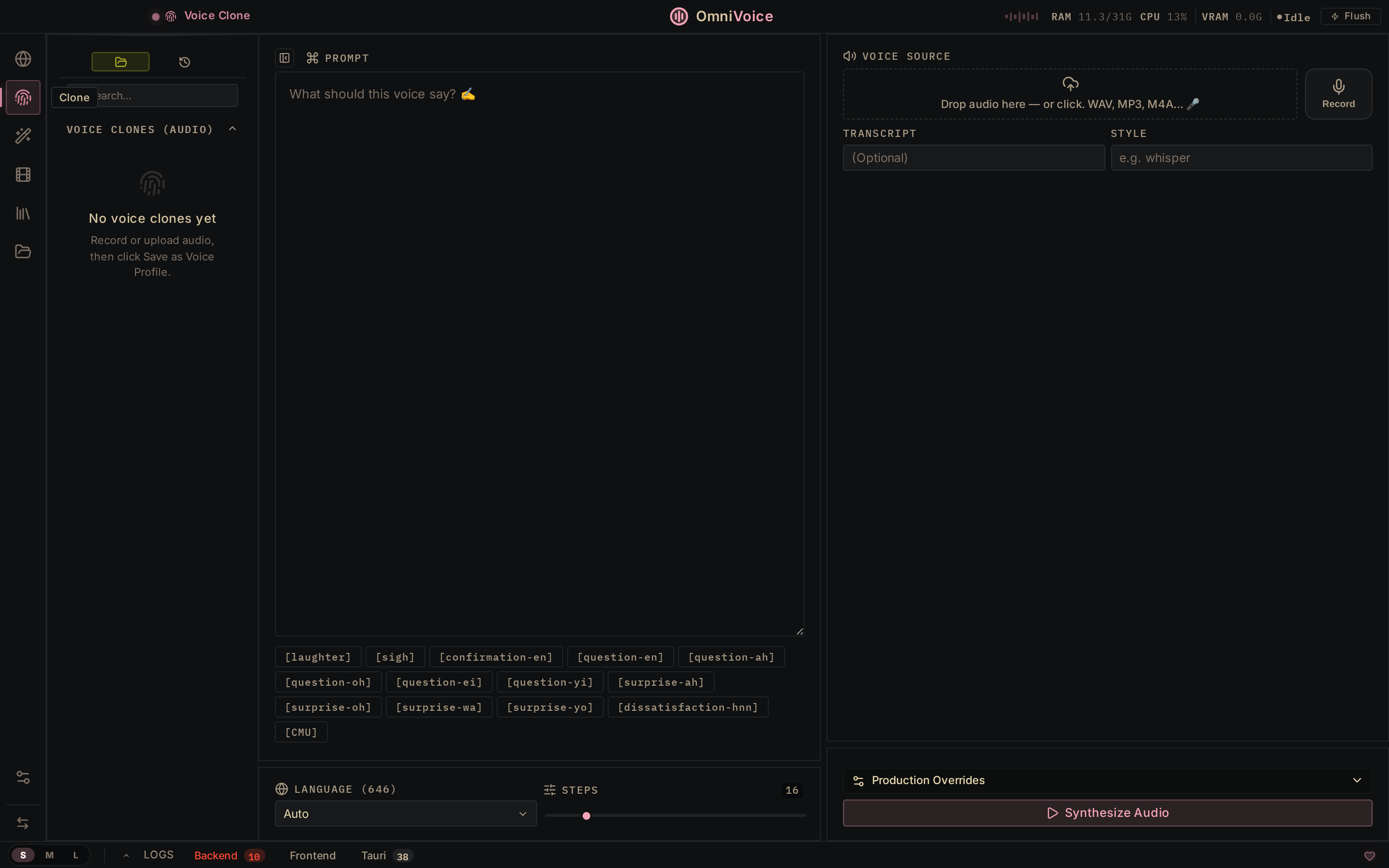
声音设计
从头构建新声音——性别、年龄、口音、音高、风格。
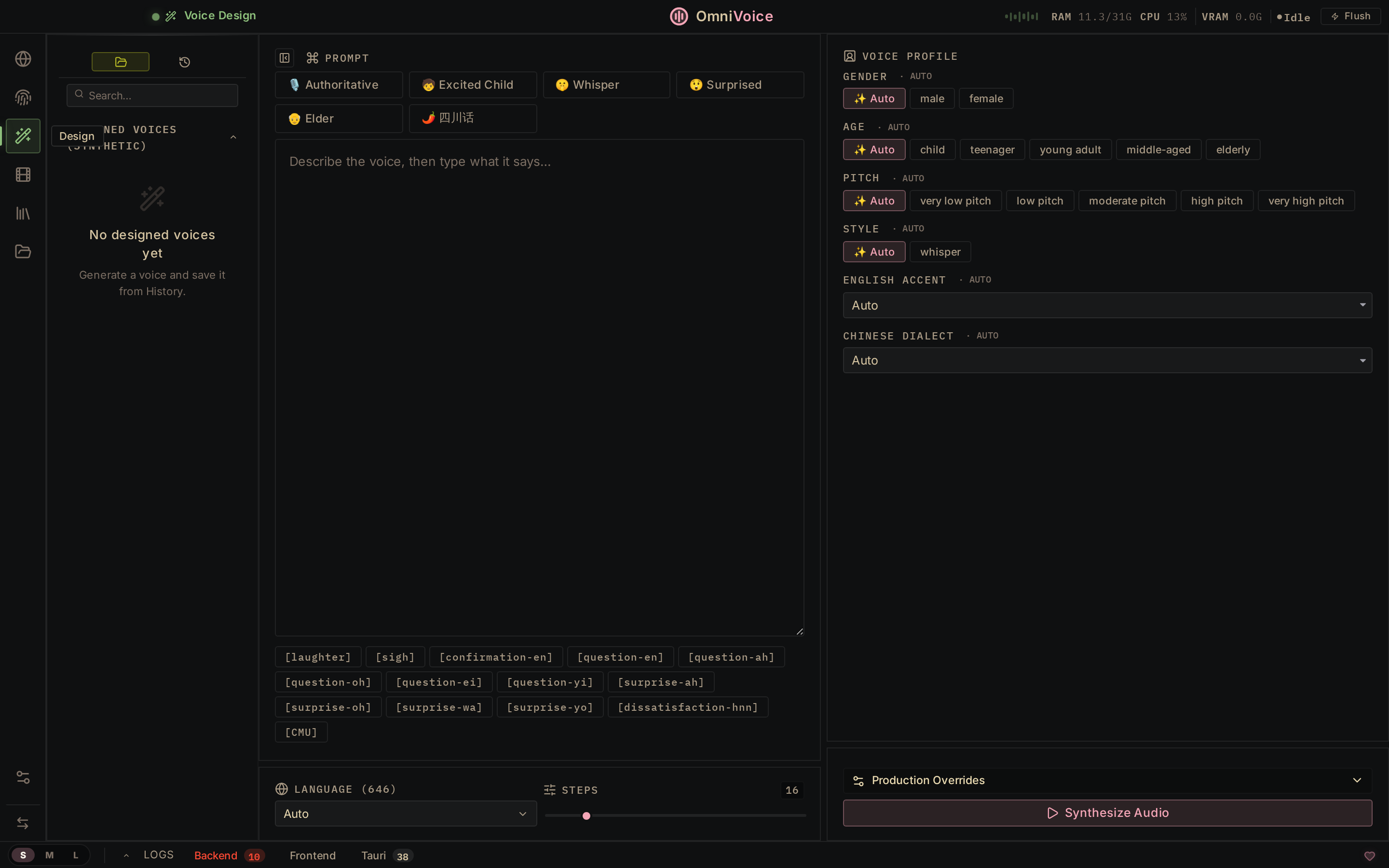
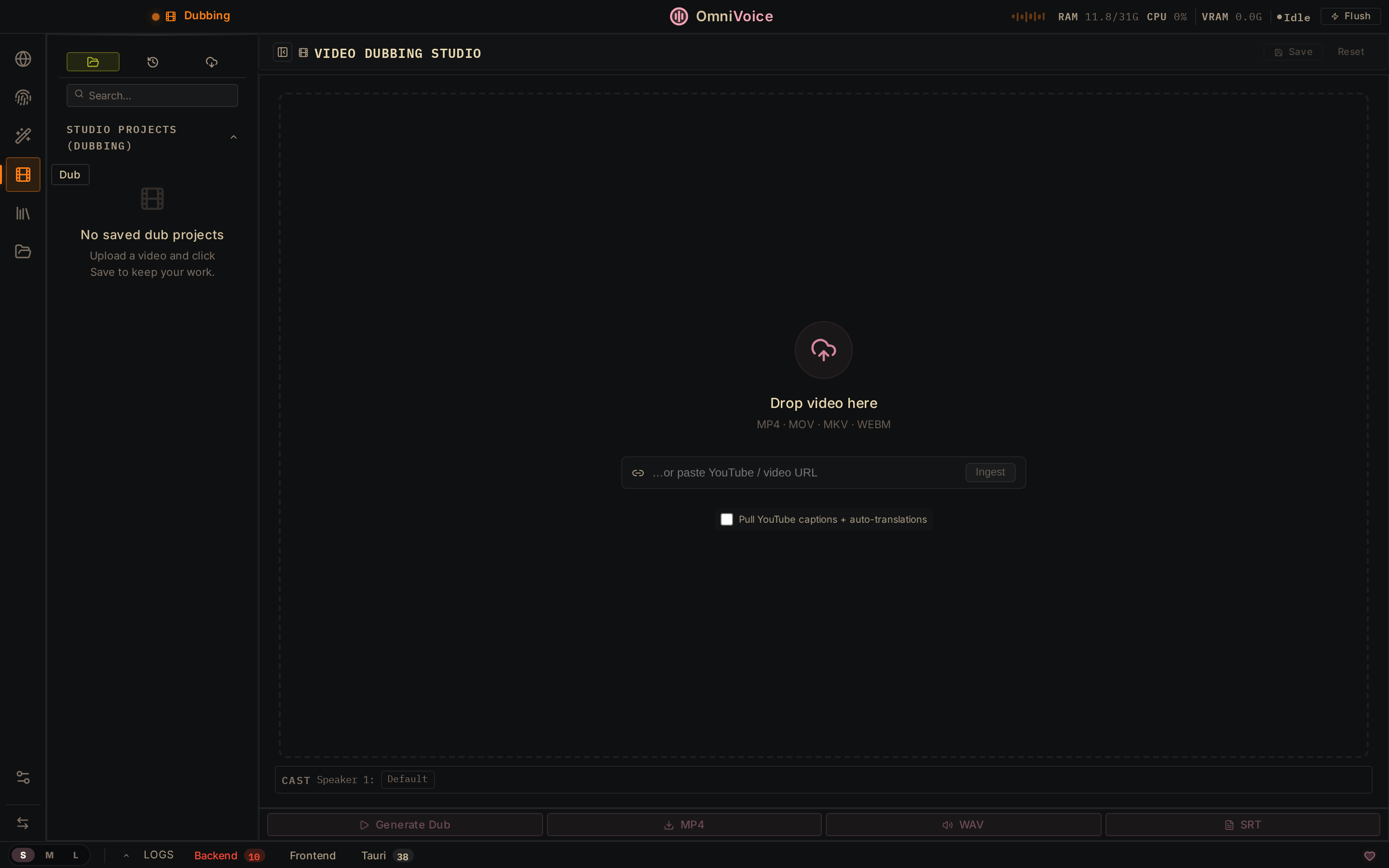
视频配音
上传或粘贴 YouTube 链接。转录、翻译、重新配音、导出。
声音库
搜索 YouTube、浏览分类、下载片段、构建你的收藏。

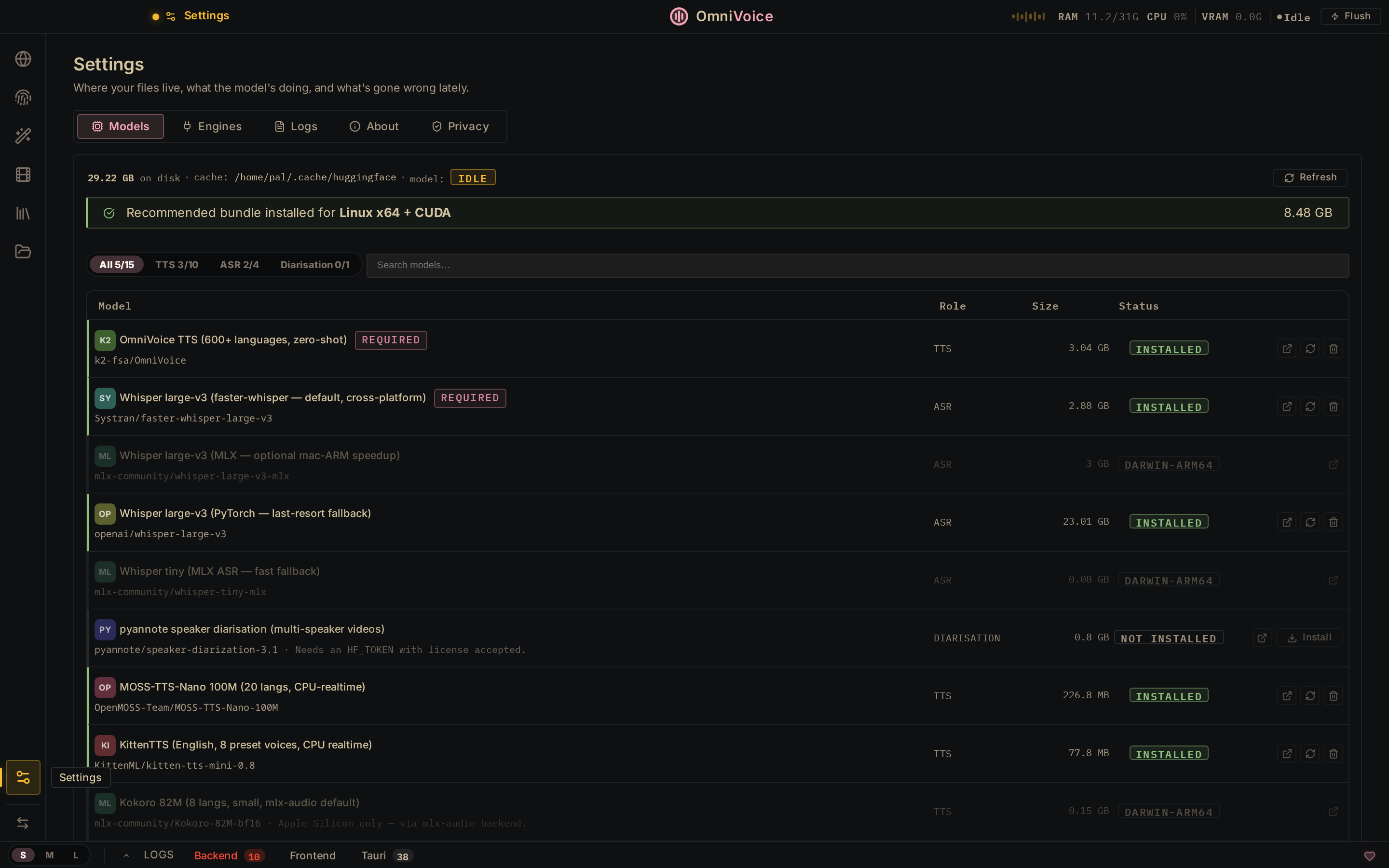
设置 → 模型
15 个模型。一键安装。自动检测你的平台(CUDA / MPS / CPU)。
项目
配音项目、声音配置、生成历史、导出——全部可搜索。
设置 → 日志
实时后端、前端和 Tauri 运行时日志。筛选、刷新、清除。
常见问题
这款产品真的能和ElevenLabs媲美吗?
对于语音克隆和配音,OmniVoice 的确可以胜出——它采用最先进的扩散式 TTS 模型,支持 646 种语言(ElevenLabs 仅支持 32 种)。在大多数应用场景下,两者的质量不相上下。ElevenLabs 的优势在于其完善的云 API 和预制语音库。而 OmniVoice 则在隐私性、成本、语言覆盖范围和可定制性方面更胜一筹。
它能在苹果芯片(M1/M2/M3/M4)上运行吗?
是的。MPS 加速功能会自动检测。针对 Apple 硬件,Whisper 推出了 MLX 优化版本,可实现更快的转录速度。
我需要多少显存?
最低内存要求为 4 GB。内存 ≤ 8 GB 时,TTS 模型会在转录过程中自动卸载到 CPU 上运行。内存 ≥ 8 GB 时,所有操作都会同时在 GPU 上运行。完全没有 GPU?CPU 模式也能运行,只是速度会慢一些(TTS 速度大约慢 3 倍)。
我可以将其用于商业用途吗?
个人及非商业用途免费。商业用途需付费授权——请参阅“授权许可”。企业用户可享受 30 天免费试用。
支持哪些语言?
OmniVoice 模型支持 646 种语言的文本转语音 (TTS)。转录 (WhisperX) 支持 99 种语言。翻译覆盖范围取决于目标语言对。































 浙公网安备 33038202002266号
浙公网安备 33038202002266号